Induction is one of the weirdest proof techniques around. It took me forever to fully understand it. It’s complicated; it has all these different parts; and it’s difficult to understand how it even accomplishes its stated goal of proving that something is true for all natural numbers. Most people probably have the following three questions the first time they see induction:
- WTF did I just see?!
- How did that even work?!
- How did they ever come up with this?
I know I did. It’s unfortunate that induction is so hard to understand, because it’s also extremely important for computer science; in fact, probably 90% of all the proofs I’ve ever seen in theoretical computer science were proofs by induction. That’s because induction captures the idea of doing something repeatedly, just like the loops and recursion that are used all over the place in programs. But when my school covered induction (in a lower-division discrete math grab bag course), the teacher just slapped it on the board and said “There it is.” Most of the class just memorized how to do simple induction proofs, and by the time I was in upper-division theory of computation and algorithms classes, the professors were expecting proofs out of us that most of the students had no idea how to write, because they never learned how to apply induction to anything more complicated than 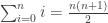
That’s why I’m going to try and give a little insight into induction. Once I knew what I’d just seen, how it even worked, and how anyone ever came up with it, I saw that induction is actually a fascinating and elegant proof technique. I also, eventually, saw why it’s so important for computer science, but most CS classes treat math as a tool, like vi or Git, that you learn on your own time; throw up some formulas and some examples to copy, and everyone goes home and memorizes it. I learned what I learned about induction from math classes, and I’m going to try and put it out there so all CS majors can learn to appreciate induction.
An Example, just to set the stage
First, though, I am going to make a total liar of myself and walk you through an example. That’s because induction has so many parts to it that I want to make sure we’re all on the same page about that before I start going into the background. I’m going to assume that you’ve seen all the simple examples involving sums, and that you’re ready for something a bit more complicated. So let’s talk about binary trees. Actually, let’s talk about full or perfect binary trees. And here one is:
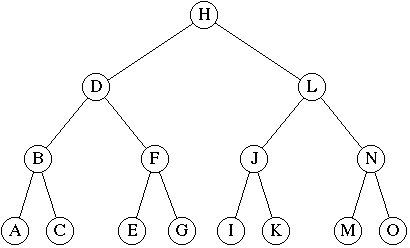
(Source: http://www.csee.umbc.edu/~chang/cs202.f98/readings/trees/trees.html. Go there if you’re unclear at all about trees.)
In textbooks, the statements to be proved are always provided for you, free of charge, but in general you have to actually do some digging to figure out just what you’re going to prove. To make this more real, let’s suppose that our binary tree represents something—for example, we can say it’s a decision tree for some kind of simple AI program that decides whether it likes a car or not based on what features the car has. Each node is a feature; taking the left branch means yes, the car has the feature, while taking the right branch means no, the car doesn’t have the feature. Something like this:

(I know, no one uses CD players anymore, but fitting “stylish adaptive media center with voice-activated controls and iCharging Station” onto the picture just wasn’t worth it.)
You can see that when we add a feature, we don’t just add one new node for that feature. We had just one node for leather seats, but we needed two for air conditioning—one for the reality where we had leather seats, and one for the reality where we didn’t. Then when we added CD player, we needed four nodes—one for the reality where we had leather seats and air conditioning, one for the reality where we had leather seats and no air conditioning, one for the reality where we didn’t have leather seats but had air conditioning, and one for the reality where we had neither leather seats nor air conditioning. You can probably see that if we add another feature—say, power windows—we’ll need eight new nodes: one for leather seats, air conditioning,CD player, power windows; one for leather seats, air conditioning, CD player, no power windows; one for leather seats, air conditioning, no CD player, power windows; one for…
Let’s say that the children of the bottom feature nodes are decision nodes–each one represents a decision of yes, buy the car, or no, don’t buy it. Then we could have something like this:
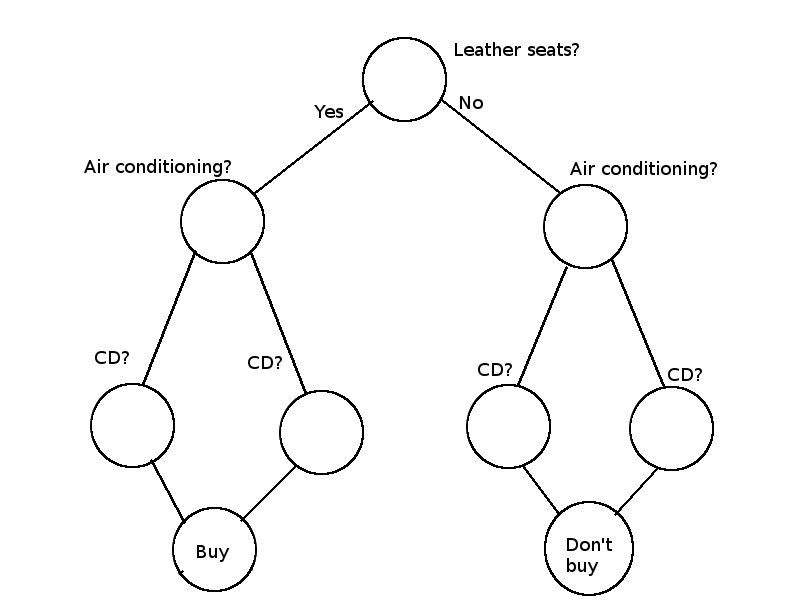
In this case the decision of whether to buy or not is based only on whether the car has air conditioning, but we could have made a separate decision for every possible combination of features, and then we’d have eight decision nodes down there at the bottom.
We can see just from this small example that the number of nodes we have to store gets big pretty quickly as we add more and more choices, but just how quickly? What we’d like is some kind of formula where we plug in the number of features we want to consider and get back how many nodes that will require. That way, if we know how big a node is and how much memory our computer has, we can figure out how many features we can have before it crashes the computer.
(I hope it’s obvious that having a formula is better than just trying some random number of features, seeing if the program crashes, and trying some random smaller number if it does. Even an approximation formula that gets you in the right ballpark is helpful.)
If you try out some examples—adding features, drawing in the new nodes, and counting them—you’ll probably notice a pattern: each feature requires exactly twice as many nodes as the feature before it. Leather seats only required one node, but air conditioning required 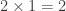


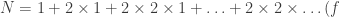
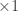

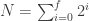
Let’s not be hasty
Now that you’re a big time computer scientist, you’re not allowed to assume that something always works just because it seems to work for a few small examples. This is where induction comes in.
While it might seem obvious that every level of the tree (which corresponds to a feature in our example; again, see a tutorial on trees if you’re drawing a blank on this term) has twice as many nodes as the level before it, we can’t actually be sure of this. There are some truly bizarre patterns and arbitrary cutoff points in math, where things that seem the same are totally different, or things that seem different are really the same thing in disguise. We’ll see an example of this later when we talk about the PCI and the well-ordering principle. For other examples, check out finding the roots of polynomials (something magical happens between a polynomial of degree 4 and one of degree 5) or graph coloring (between 3 and 4 here).
We have two assumptions in the formula above: that every level of a binary tree has twice as many nodes as the level above it, and that the sum of nodes in every level of the tree is the total number of nodes in the tree. Both of these need to be proved before we can say for sure that the formula above is always true, no matter how many levels our tree has.
So first of all, let’s prove that every level of a tree has twice as many nodes as the level before it, or equivalently, the 
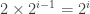
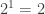
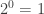
This is a fine point to keep in mind: the base case can start anywhere. It does not have to start at 1 or 0. It could start at 22, or 69 (if you’re that sort of person), but remember that if you put the base case at 69, you have only proved the theorem for when the relevant quantity is 69 or higher. If we chose to start this example at 69, then our proof would only show that if the tree has 69 or more levels, every level past level 69 has twice as many nodes as the previous level. So while you can bring dorm room humor into theoretical CS if you want to, you’re really just hurting yourself in the end, because you haven’t proved that the theorem is true for a tree with 68 or fewer levels. Here we’re starting at 0, so every tree that has a root (i.e. pretty much all of them) has the property that level 
So we have our base case. Next is our inductive hypothesis. This is the weirdest step for beginners to understand. It blew my brain for several months after I first learned about induction. That’s because it doesn’t actually involve anything factual. Instead, the inductive hypothesis and inductive conclusion together do pretty much what you do when your friend says he was abducted by aliens and you reply “Assuming aliens existed” (your hypothesis), “they wouldn’t fly across the galaxy just to see you naked” (your conclusion). Induction, though, does more than this, because we have the base case, so we know that the theorem is true in at least one case; it’s as if we said “Here’s an alien. He says he wouldn’t fly across the galaxy to see you naked (base case). Assuming more aliens exist (hypothesis), they wouldn’t fly across the galaxy to see you naked either (conclusion).” In future parts, we’ll see the mathematical formalism behind this, which will show why an induction is a valid proof and not just an invalid generalization based on a single example.
So for our inductive hypothesis for the tree level example, we assume that 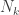



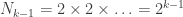

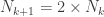
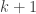
From here it’s really just algebra. We’re trying to prove that 
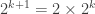


Now we need to show the second thing, that in a tree with 
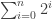
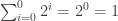
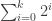

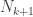
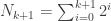

We know that 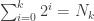
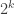
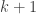
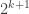
What was the point?
I walked through that whole example, from conception to culmination, because I wanted to give you some kind of idea about why induction is used in computer science. We saw that the binary tree was something we could keep building by applying the same rules repeatedly (building a new level by giving each leaf in the previous level two children). That sounds a lot like a loop! Indeed, if we were building that tree in a program, we’d probably have a loop that would read a list of car features and build the tree up by adding children, making levels for each feature. All we had to do was number each level in our tree; then we could use induction, and prove that no matter how many levels the tree has, the same properties still apply.
As we’ll see in the next part, you can use induction any time your objects can be numbered in some way using the natural numbers so that there’s an operation to transform the
Summary
- Induction is a very important proof technique in computer science, because it captures the idea of doing something repeatedly. Loops and recursion can both be proven correct using induction.
- Proofs by induction have three parts: the base case (“This alien says he wouldn’t travel across the galaxy to see you naked.”), the inductive hypothesis (“Assuming that more than one alien exists…”), and the inductive conclusion (“…they wouldn’t travel across the galaxy to see you naked either.”).
